多个厂商提供免费 token,会拿用户的数据训练模型吗?
越来越多的 AI 厂商开始推出一种新的商业模式:用户可以通过分享自己的使用数据,换取免费的 API 调用额度。个人用户如果不在乎日常聊天的数据,看起来是一个双赢的局面 —— 用户获得了免费的计算资源,而厂商则获取了珍贵的用户数据。
OpenAI:分享内容获取免费 Token
1
https://platform.openai.com/settings/organization/data-controls/sharing
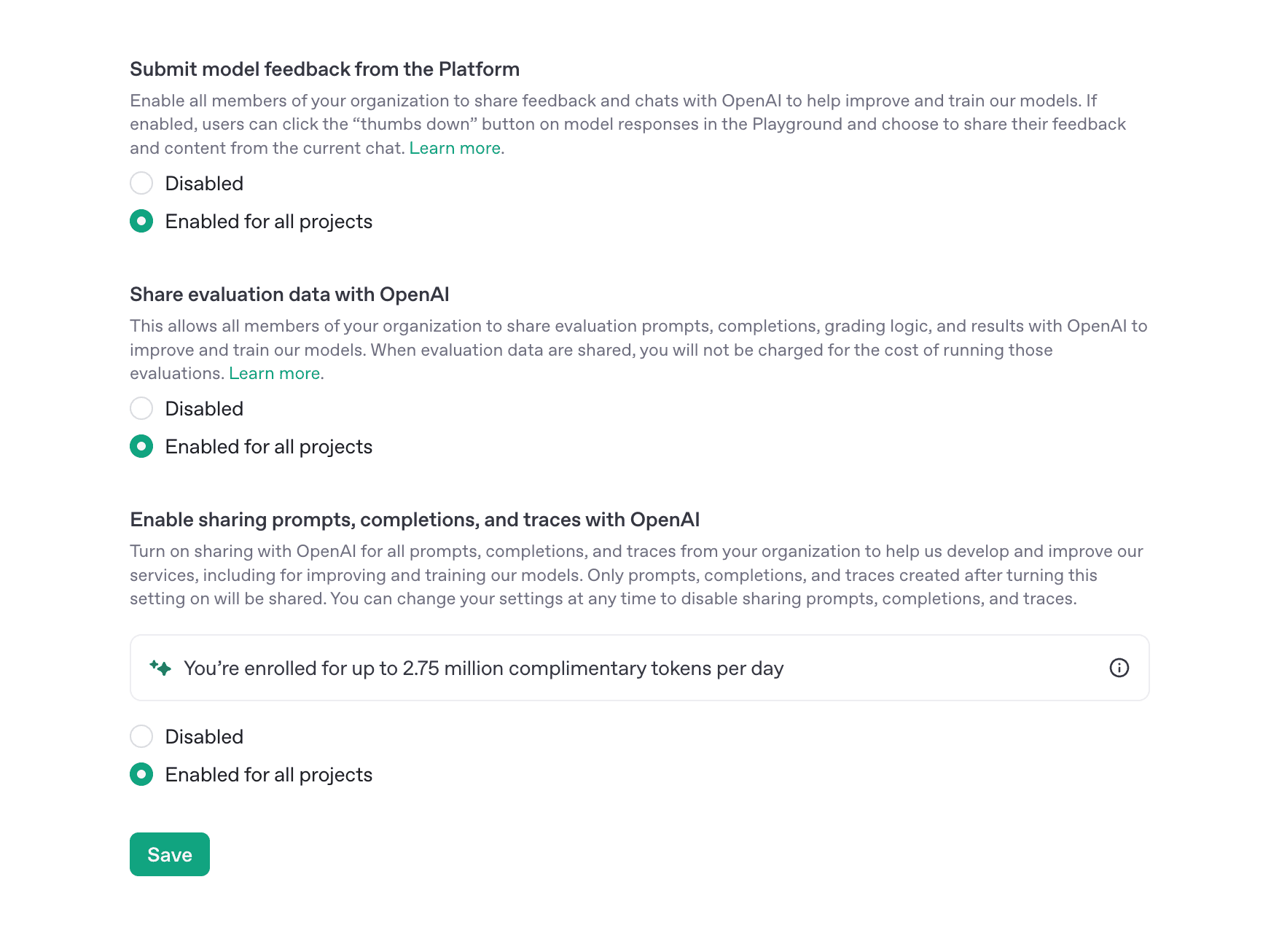
OpenAI 在其平台设置中提供了多个数据共享选项,用户可以通过启用这些选项来获取免费的 Token 额度:
- 提交模型反馈:允许组织的所有成员分享反馈和聊天记录,帮助改进和训练模型。
- 分享评估数据:允许组织成员分享评估提示、完成内容、评分逻辑和结果。启用此选项后,评估运行的费用将免除。
- 启用提示、完成和跟踪的共享:将组织的所有提示、完成和跟踪分享给 OpenAI,以帮助开发和改进服务。启用后,每天最多可获得高达 1000 万个免费 Token。
DeepSeek:用户数据服务优化
DeepSeek 在其服务条款中明确表示:“在经安全加密技术处理、严格去标识化且无法重新识别特定个人的前提下,我们可能会将服务所收集的输入及对应输出,用于本协议下服务的优化以及统计分析、问题排查、安全风控等目的。”
虽然没有直接提供 Token 奖励,但这种数据使用政策是用户使用其服务的隐含条件。 
X.ai:数据共享获取月度赠金
X.ai(前身为 Twitter)提供了一个”免费积分计划”,参与的团队每月可获得 $150 的免费 API 积分。条件是:
- 选择加入数据共享计划
- 同意与 X.ai 分享你的 API 请求
- 在选择加入前已经在 API 上花费至少 $5,可以参考:
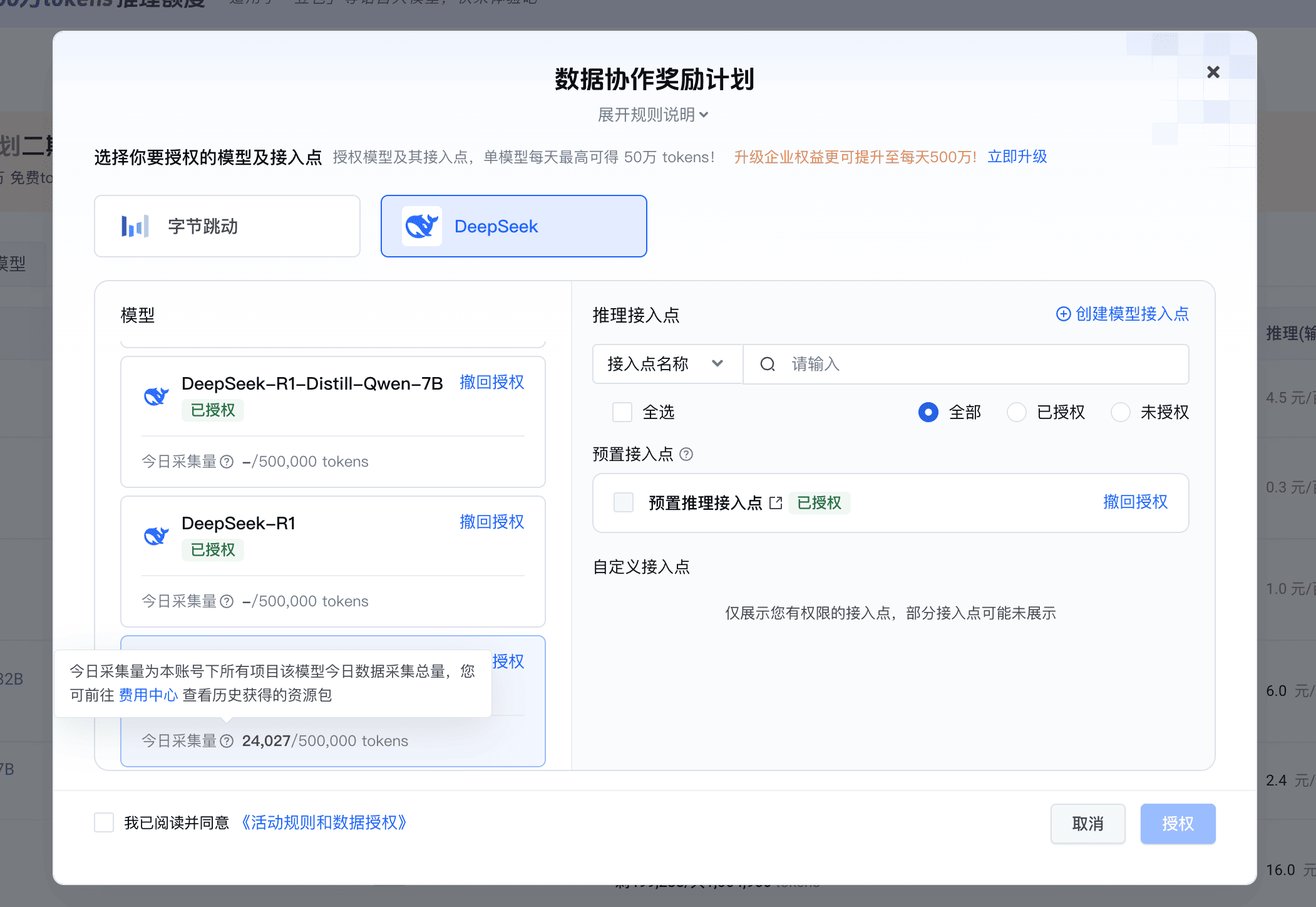
火山云:每日免费 Token
火山云采取类似策略,用户共享数据后,每天最多可获取 50 万个免费 Token,可用于 DeepSeek R1、V3 等模型。
大模型厂商如何使用共享数据?
当我们将对话数据分享给这些 AI 公司时,他们到底会拿这些数据做什么?这是一个许多用户关心的问题。为了寻找答案,我向 OpenAI 和 DeepResearch 询问了相关情况,得到了以下洞见。
哪些数据适合训练 LLM?
并非所有文本数据都适合直接用于训练大型语言模型。通常来说,公开、高质量、通用性强的文本更为适合,比如:
- 新闻、百科、科普文章(提供事实性知识)
- 小说和文学作品(提供语言多样性)
- 代码库(提供编程相关文本)
- 公开论坛问答(提供互动式语言)
对于用户生成的对话内容是否用于训练,则取决于数据的来源和性质:
公共领域的对话数据
许多模型在训练时确实包含了对话形式的数据,但通常来自公共互联网论坛或 QA 网站,而非私密聊天。例如:
- Meta 的 LLaMA 1 包含从 StackExchange 网站抓取的问题和回答对话
- Reddit 等论坛的公开讨论(经过过滤后)也被一些模型使用
这些公开可获取的用户对话内容在适当清洗后可以作为训练语料的组成部分,丰富了模型对人类对话的理解。
私人聊天记录
普通用户在聊天机器人上的私人对话,未经用户许可通常不会被直接用于训练模型,原因有几点:
- 隐私和法律问题
- 这类对话往往针对性很强,缺乏普遍适用性
- 可能包含大量口语、拼写错误、断断续续的对话,对模型预训练的边际价值不高
但有一个值得注意的例外:如果收集了足够规模且多样的用户提问-回答对话,且这些对话质量较高,那么作为指令微调的数据集可能非常有用。例如,OpenAI 曾使用用户提供的 API 请求来构建微调数据集,然后由人工撰写高质量回答用于训练 InstructGPT 模型。
用户对话数据的其他技术价值
即使大部分公司不直接将用户对话数据用于模型参数训练,这些聊天数据在模型开发流程中仍有重要的技术价值:
模型对齐(Alignment)
真实用户对话中往往能反映模型的不足和不当行为。开发者可以利用对话日志来改进模型的对齐性:
- 收集模型不当回复的实例,完善安全策略和惩罚机制
- 分析用户提出但模型无法很好回答的问题类型
例如,Anthropic 虽然不将用户数据直接训练模型,但如果用户对某些回复评价负面,这些被标记的内容会用于改进 Claude 的滥用检测和过滤系统。OpenAI 也可能根据 ChatGPT 用户反馈来调整模型的回复风格。
模型评估
用户真实的提问和对话内容可以作为评估模型性能的宝贵资源:
- 从大量聊天日志中汇总常见问题或有代表性的交互场景,构建内部测试集
- 用户行为(如是否追问、是否终止对话、评分反馈等)为评估模型质量提供了隐式指标
相比于纯学术基准测试,真实用户数据的评估更贴近模型实际应用表现。
提示工程和产品调优
用户与聊天模型的交互能启发提示工程(Prompt Engineering)和产品功能改进:
- 发现哪些提示更容易引发模型好的回答,哪些可能导致误解
- 改进模型的系统提示或官方推荐用法
- 设计预置模板或一键提示,帮助用户更方便地下达复杂指令
- 发现新需求,考虑加入新功能或工具
研发人类反馈机制
聊天过程中用户提供的显性反馈(评分、举报)是极其重要的信号,常被用于强化学习流程(RLHF)的奖励模型训练:
- 不是直接训练主 LLM 参数,而是训练辅助的奖励模型或过滤模型
- 用户对话数据丰富反馈样本,使 RLHF 阶段更贴近真实人群偏好
总结
大模型厂商提供的数据共享换取 Token 的模式,本质上是一种数据与计算资源的交换。这种交换并非简单的”免费午餐”,而是一种复杂的数据经济关系。
厂商即便不会直接利用用户的数据进行模型的训练,但是对于在 模型对齐、性能评估、提示优化、反馈学习等环节扮演着重要角色
作为用户,我们需要在便利与隐私之间找到适合自己的平衡点,做出明智的选择。