手机端离线访问 DeepSeek R1 蒸馏模型
手机端离线访问 DeepSeek R1 蒸馏模型
手机端离线访问 DeepSeek R1 蒸馏模型
手机端部署大模型这里需要安装一个支持部署本地模型的软件,这里推荐两个
1. fullmoon
fullmoon 支持平苹果全家桶,iOS/iPadOS/macOS 都可以使用。 缺点是模型数量较少,是个比较新的一个软件。大模型版本是 1.5b-4bit, 1.5b-8bit 两个版本。
优点是输出速度很快。
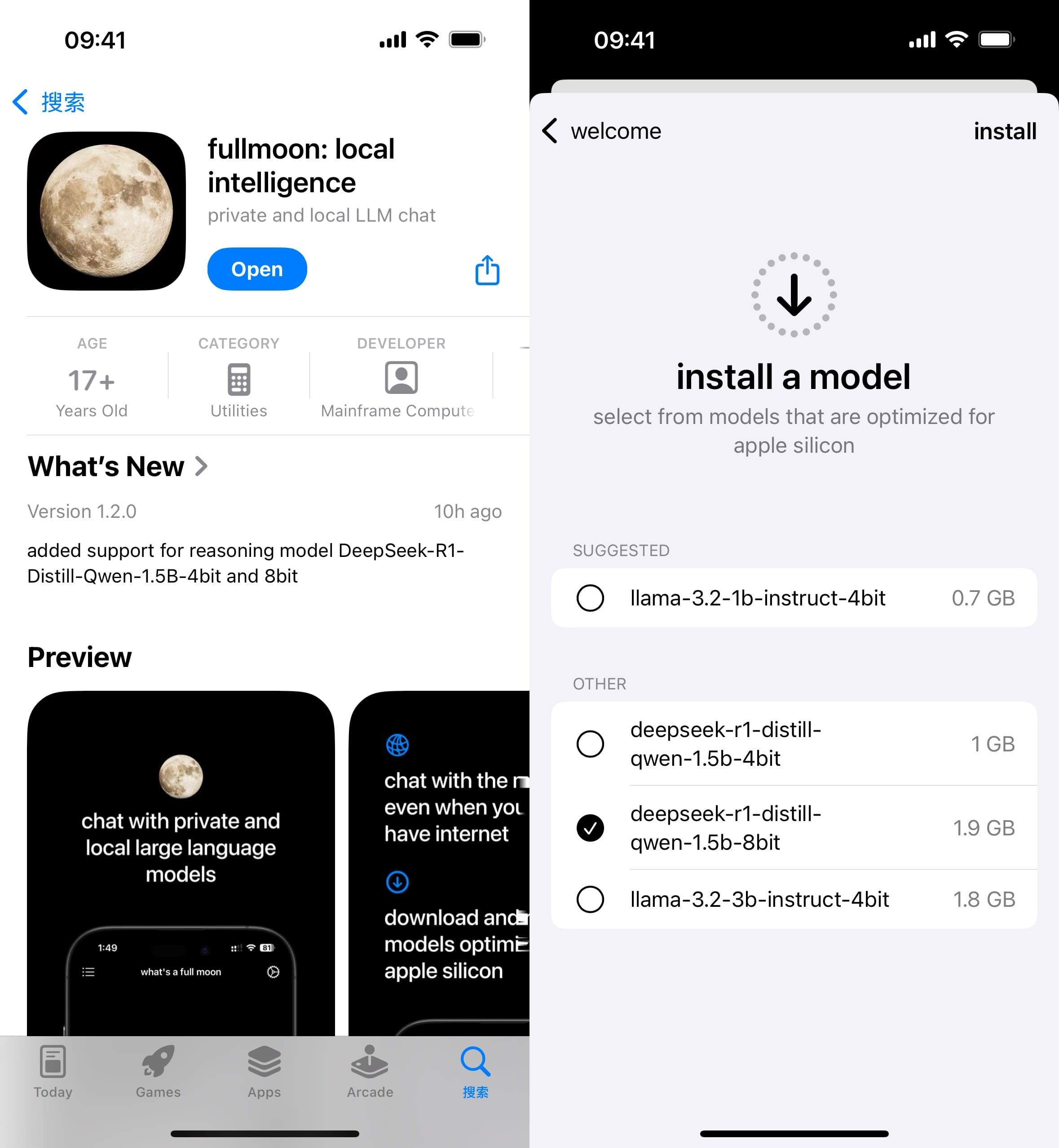
2. PocketPal
PocketPal 是一个开源项目,地址 https://github.com/a-ghorbani/pocketpal-ai 支持 iOS 和 Android 。 可以直接从 App Store 或者 Google Play 应用商店下载。 这个软件可以下载的模型非常的多,因为这个可以直接从 Hugging Face 下载。
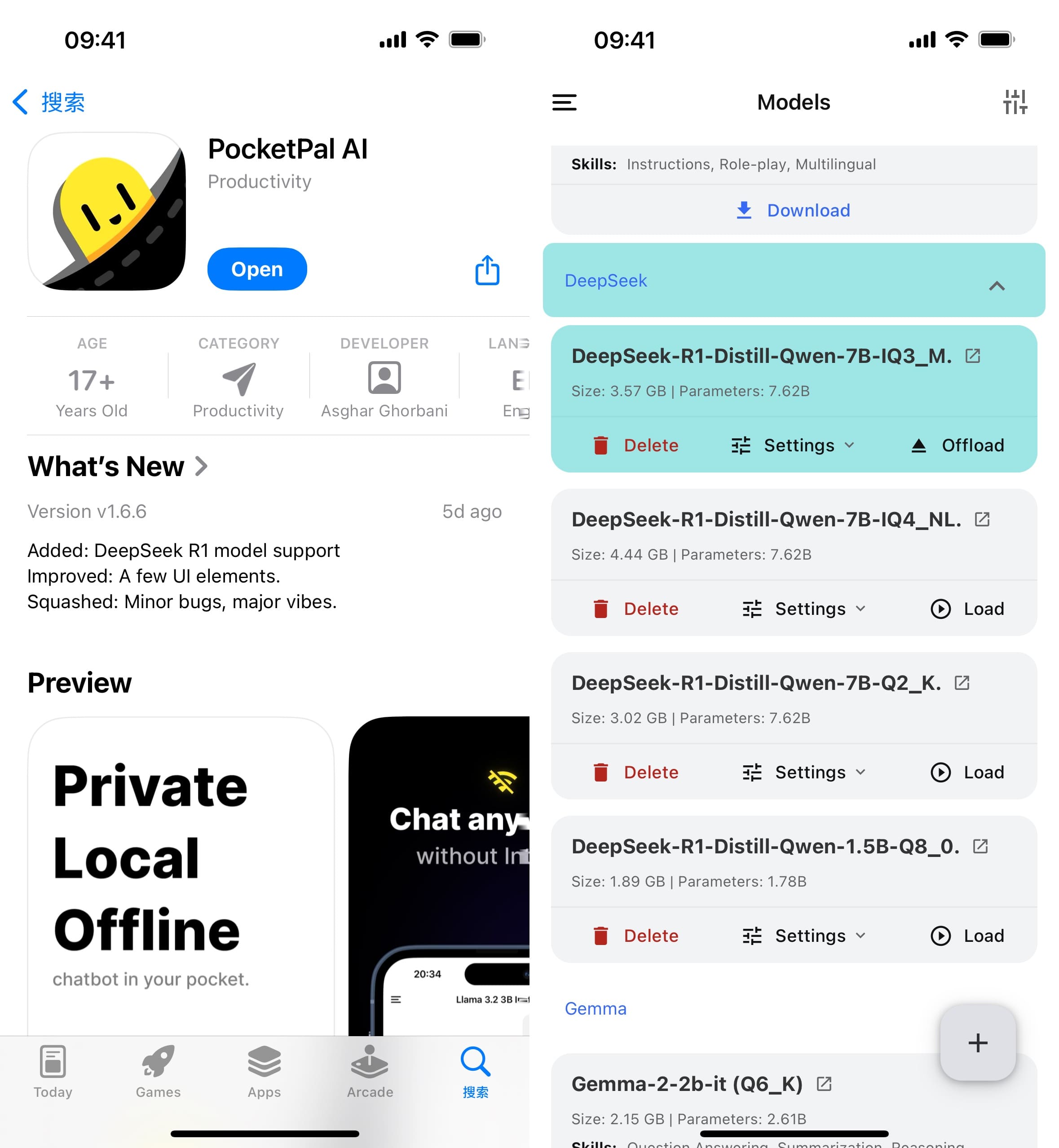
点击添加模型后,可以选择从 Hugging Face 下载
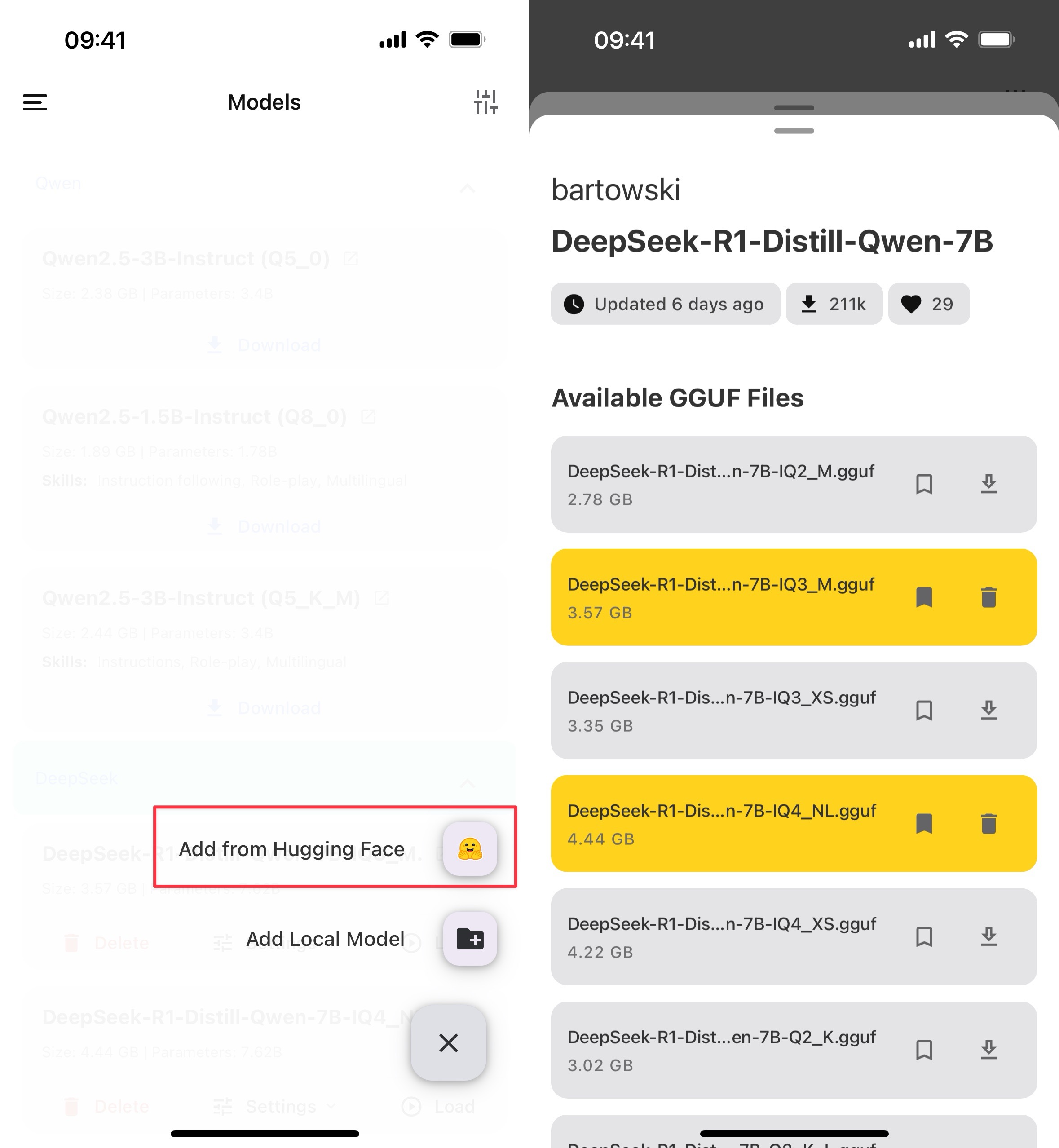
PocKetPal AI 手机模型选择
这里的模型选择,一般体积越大的理论效果越好,占用资源也越多。 Q2 表示使用 2-bit 量化, Q4 表示使用 4-bit 量化, Q8 表示使用 8-bit 量化。本质是一种数据压缩技术。越大越精确,占用资源也越多。可以理解为影响的是模型的精确度,比如逻辑推理、知识回答、创意写作等。
M/S/XS 标识模型的尺寸,M 表示中等,S 表示小,XS 表示最小。一般可以理解为模型的 “知识容量”。同一个模型,同一个量化下,尺寸越大效果越好。
我的 8GB 内存的手机(iPhone 16),如果选择 DeepSeek-R1-Distill-QWen-7B-Q2 的模型,token输出速率在 6.59 token/s 左右。没办法用的地步,而且输出还不是很稳定,模型不是很听话(指令遵循能力很差)。
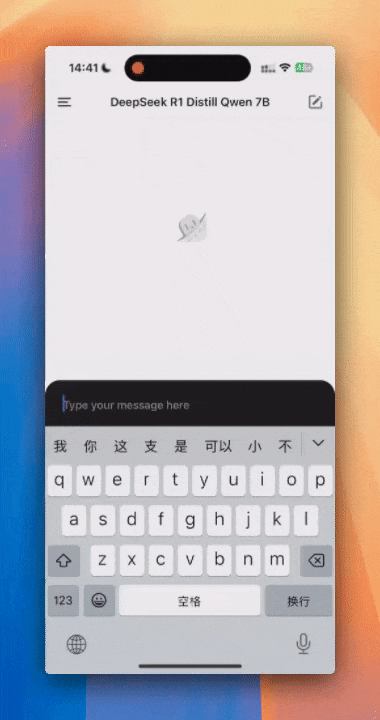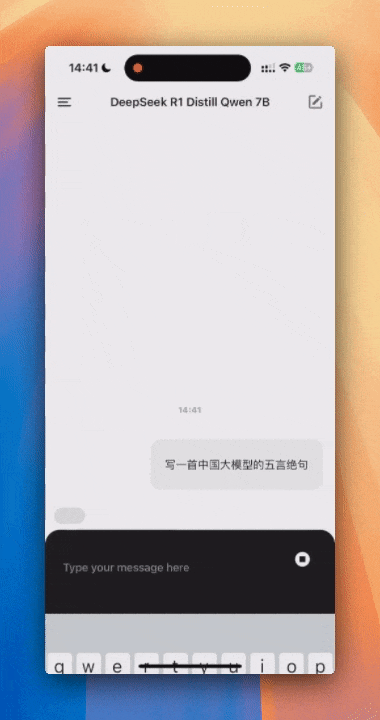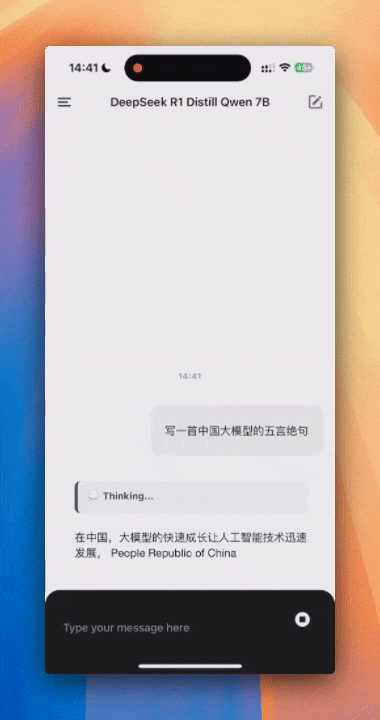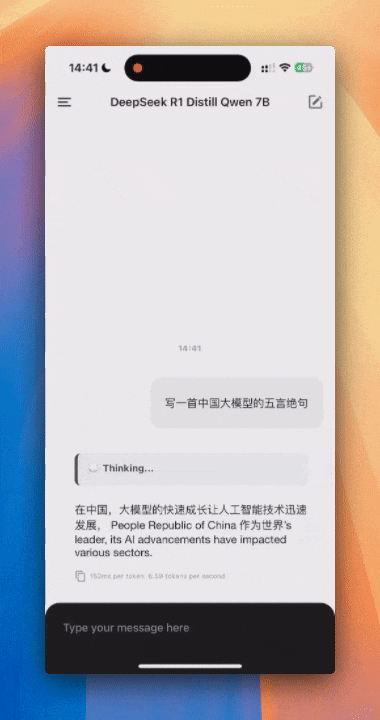
DeepSeek-R1-Distill-Qwen-7B-Q3 的模型,token输出速率在 2 token/s 左右。速度非常的慢,基本不可日常使用,但是输出质量好了很多,有思考过程了。 
总结:
- 可以折腾
- 手机端跑的本地大模型,就目前这个 deepseek-r1 蒸馏的小模型。 如果还没有特别优化的版本,在手机上日常用效果不理想。
本文由作者按照 CC BY 4.0 进行授权