2024 年我们对大语言模型的认知
我们在 2024 年从大型语言模型中学到的事
2024 年,大语言模型领域发生了很多事情。以下是我们在过去 12 个月中对这个领域的认知,以及我试图识别的关键主题和重要时刻。
这是我对 2023 年回顾 的续篇。
本文内容:
- GPT-4 的门槛被彻底打破
- 一些 GPT-4 级别的模型可以在我的笔记本上运行
- 大语言模型价格暴跌,得益于竞争和效率提升
- 多模态视觉能力已经普及,音频和视频开始崭露头角
- 语音和实时摄像头模式让科幻变成现实
- 提示词驱动的应用生成已成为一种商品
- 最佳模型的普遍访问仅持续了短短几个月
- “智能体”仍然没有真正实现
- 评估变得非常重要
- Apple Intelligence 表现不佳,但 Apple 的 MLX 库非常出色
- 推理扩展模型的崛起
- 目前最好的大语言模型是在中国以不到 600 万美元的成本训练的吗?
- 环境影响变好了
- 环境影响变得更糟了
- 垃圾内容之年
- 合成训练数据效果很好
- 大语言模型的使用变得更加困难
- 知识分布极不均衡
- 大语言模型需要更好的批评
GPT-4 的门槛被彻底打破
在我 2023 年 12 月的回顾中,我写道我们还不知道如何构建 GPT-4 - OpenAI 的最佳模型当时已经快一年了,但其他 AI 实验室都没有产出更好的模型。OpenAI 掌握了什么我们不知道的东西?
我很欣慰这种情况在过去 12 个月里完全改变了。现在有 18 个组织的模型在 Chatbot Arena Leaderboard 排行榜上的排名高于 2023 年 3 月的原始 GPT-4 (排行榜上显示为 GPT-4-0314) - 总共有 70 个模型。
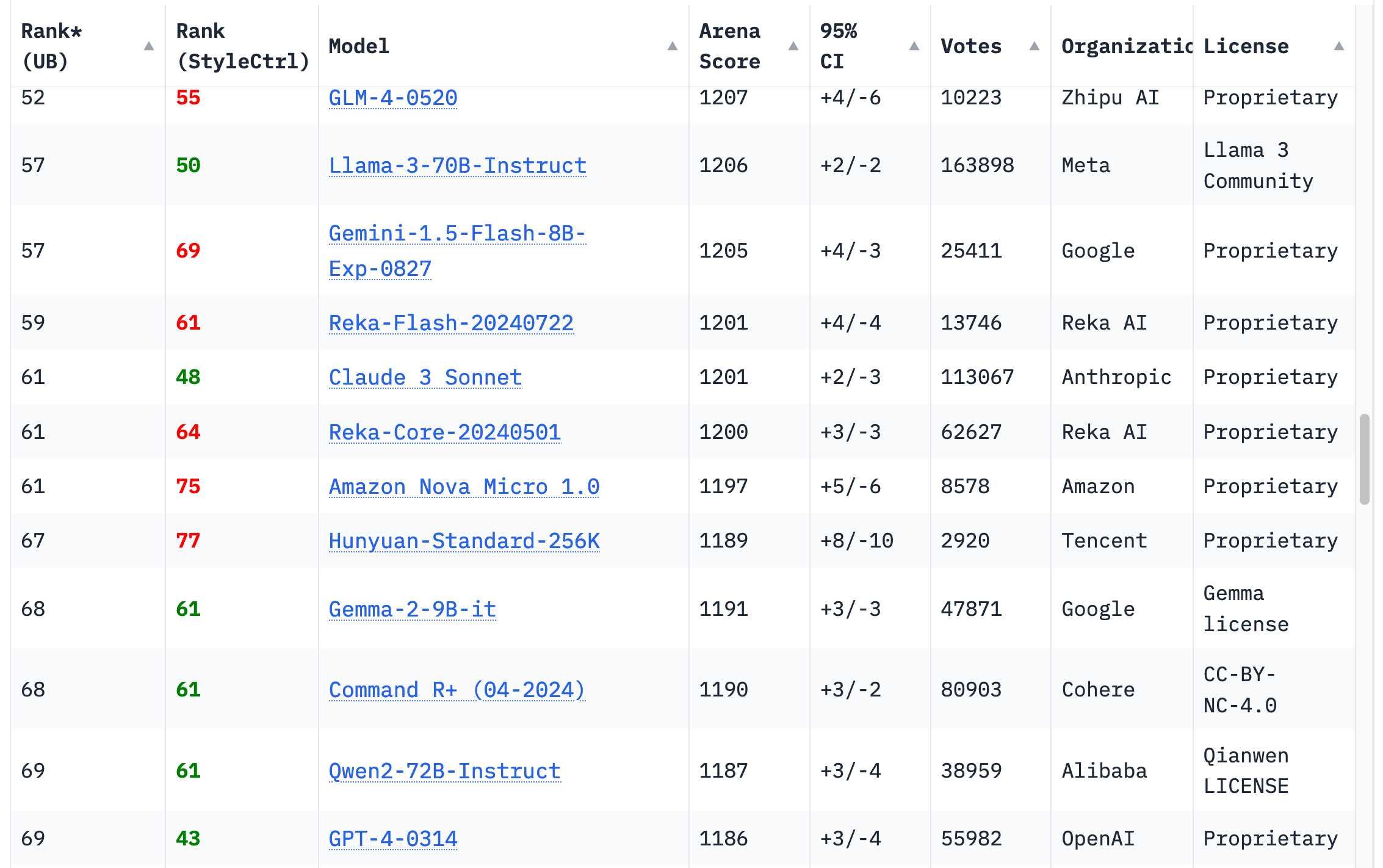
最早的是 Google 的 Gemini 1.5 Pro,于 2 月发布。除了产生 GPT-4 级别的输出外,它还为该领域引入了几个全新的功能 - 最显著的是其 100 万 (后来达到 200 万) token 的输入上下文长度,以及输入视频的能力。
我当时在《Gemini Pro 1.5 的杀手级应用是视频》一文中写到了这一点,这让我在 5 月的 Google I/O 开场主题演讲中短暂露面。
Gemini 1.5 Pro 还展示了 2024 年的一个关键主题:上下文长度的增加。去年大多数模型接受 4,096 或 8,192 个 token,值得注意的例外是 Claude 2.1,它接受 200,000 个。如今,每个严肃的提供商都有一个 10 万+ token 的模型,而 Google 的 Gemini 系列最多可接受 200 万个。
更长的输入极大地增加了可以用大语言模型解决的问题范围:你现在可以输入整本书并询问其内容,但更重要的是,你可以输入大量示例代码来帮助模型正确解决编程问题。涉及长输入的大语言模型用例对我来说比仅依赖已经烘焙在模型权重中的信息的短提示更有趣。我的许多工具都是使用这种模式构建的。
一些 GPT-4 级别的模型可以在我的笔记本上运行
我的个人笔记本电脑是 2023 年的 64GB M2 MacBook Pro。这是一台性能强劲的机器,但现在也快两年了 - 关键是,这是我自 2023 年 3 月首次在电脑上运行大语言模型以来一直在使用的同一台笔记本电脑(参见《大语言模型正在经历它们的 Stable Diffusion 时刻》)。
去年 3 月那台勉强能运行 GPT-3 级别模型的同一台笔记本电脑,现在已经运行了多个 GPT-4 级别的模型!以下是我的一些笔记:
- 11 月的《Qwen2.5-Coder-32B 是一个可以在我的 Mac 上运行的编程能力出色的大语言模型》讨论了 Qwen2.5-Coder-32B - 这是一个 Apache 2.0 许可的模型!
- 《我现在可以在笔记本电脑上运行 GPT-4 级别的模型》讨论了运行 Meta 的 Llama 3.3 70B(12 月发布)
这对我来说仍然令人震惊。我原以为具有 GPT-4 能力和输出质量的模型需要一台配备一个或多个价值 4 万美元以上 GPU 的数据中心级服务器。
这些模型占用了我 64GB RAM 中的大部分内存,所以我不经常运行它们 - 它们不会给其他任何东西留下太多空间。
它们能运行本身就证明了我们在过去一年中在模型训练和推理性能方面取得的惊人进展。事实证明,在模型效率方面还有很多低垂的果实可以采摘。我预计还会有更多进展。
Meta 的 Llama 3.2 模型值得特别提及。它们可能不是 GPT-4 级别的,但在 1B 和 3B 的规模上,它们的表现远超其重量级。我使用免费的 MLC Chat iOS 应用程序在 iPhone 上运行 Llama 3.2 3B,对于其微小的大小(<2GB),这是一个令人惊讶的强大模型。试试启动它并要求它给出”一个数据记者爱上当地陶艺家的 Netflix 圣诞电影剧情大纲”。以下是我得到的内容,速度达到了令人尊敬的每秒 20 个 token:
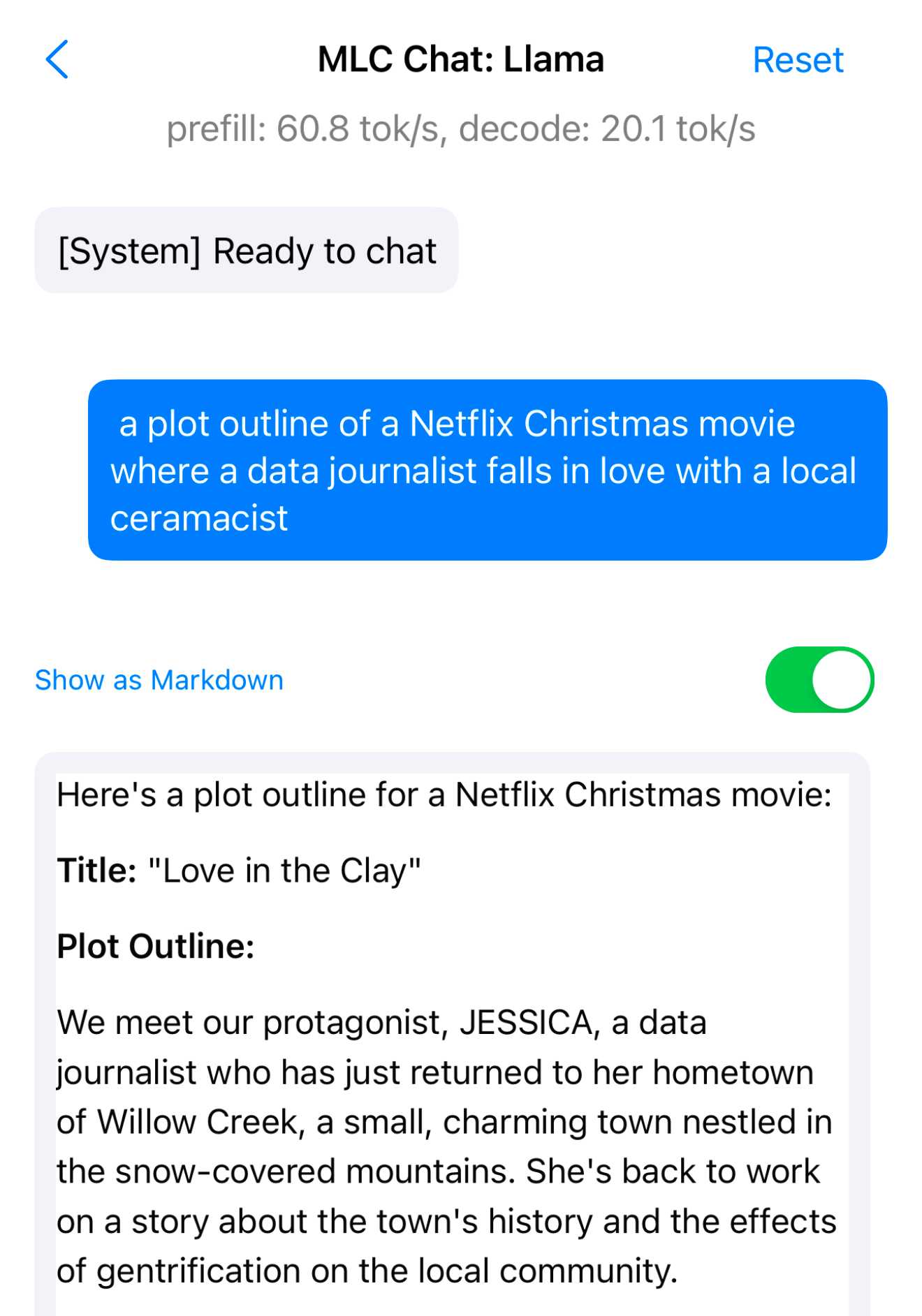
这是剩余的对话记录。它平淡而老套,但我的手机现在可以为 Netflix 策划平淡而老套的圣诞电影了!
大语言模型价格暴跌,得益于竞争和效率提升
在过去的 12 个月里,通过顶级托管大语言模型运行提示词的成本出现了戏剧性的下降。
在 2023 年 12 月 (这里是 OpenAI 定价页面的互联网档案),OpenAI 对 GPT-4 收费 30 美元/百万输入 token,对当时新推出的 GPT-4 Turbo 收费 10 美元/百万 token,对 GPT-3.5 Turbo 收费 1 美元/百万 token。
如今,30 美元/百万 token 可以让你使用 OpenAI 最贵的模型 o1。GPT-4o 的价格是 2.50 美元 (比 GPT-4 便宜 12 倍),GPT-4o mini 是 0.15 美元/百万 token - 比 GPT-3.5 便宜近 7 倍,而且能力大大提升。
其他模型提供商的收费甚至更低。Anthropic 的 Claude 3 Haiku (3 月发布,但仍是他们最便宜的模型) 是 0.25 美元/百万 token。Google 的 Gemini 1.5 Flash 是 0.075 美元/百万 token,他们的 Gemini 1.5 Flash 8B 是 0.0375 美元/百万 token - 比去年的 GPT-3.5 Turbo 便宜 27 倍。
我一直在用 llm-pricing 标签追踪这些价格变化。
这些价格下降是由两个因素推动的:竞争加剧和效率提升。效率提升对于所有关心大语言模型环境影响的人来说都非常重要。这些价格下降直接反映了运行提示词所使用的能源量。
关于 AI 数据中心大规模建设的环境影响,仍然有很多需要担心的地方,但很多关于单个提示词能源成本的担忧已经不再可信。
这里有一个有趣的粗略计算:使用 Google 的 Gemini 1.5 Flash 8B (10 月发布的他们最便宜的模型) 为我个人照片库中的 68,000 张照片生成简短描述需要多少成本?
每张照片需要 260 个输入 token 和大约 100 个输出 token。
260 * 68,000 = 17,680,000 输入 token 17,680,000 * $0.0375/百万 = $0.66 100 * 68,000 = 6,800,000 输出 token 6,800,000 * $0.15/百万 = $1.02
处理 68,000 张图片的总成本是 1.68 美元。这个价格低得离谱,我不得不计算了三次来确认我没有算错。
这些描述的质量如何?这是我用以下命令得到的结果:
1
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
对于这张在加州科学院拍摄的蝴蝶照片:

“一张两只蝴蝶在红色托盘上进食的照片
一个浅盘,可能是蜂鸟或蝴蝶的喂食器,是红色的。盘子里可以看到橙子片。
两只蝴蝶停在喂食器上,一只是深棕色/黑色的蝴蝶,有白色/奶油色的斑纹。另一只是一只大型棕色蝴蝶,有浅棕色、米色和黑色斑纹的图案,包括显眼的眼状斑。较大的棕色蝴蝶似乎正在吃水果。”
260 个输入 token,92 个输出 token。成本大约是 0.0024 美分 (这还不到一美分的四百分之一)。
这种效率的提升和价格的下降是我最喜欢的 2024 年趋势。我希望大语言模型的实用性能以更低的能源成本实现,看起来我们正在实现这一点。
多模态视觉能力已经普及,音频和视频开始崭露头角
2024 年初,视觉能力仍然是一个稀有的特性:只有 GPT-4V 和 Claude 3 提供这项功能。
到年底,每个主要的大语言模型提供商都有了视觉功能。更重要的是,这些功能变得更加强大:模型不仅可以描述图像,还可以:
- 识别图像中的文本(OCR)
- 在图像上绘制边界框来标识对象
- 分析图表和图形
- 处理扫描的文档
- 理解截图和用户界面
- 分析和调试代码截图
音频和视频功能也开始出现。Gemini 1.5 Pro 在 2 月份推出了视频功能,但直到 12 月才有其他提供商跟进。
我特别喜欢的是 Gemini 2.0 Flash 的”思考模式”,它会在处理视频时显示一个实时的思考流,让你看到它正在关注视频的哪些部分。
语音和实时摄像头模式让科幻变成现实
说到科幻:2024 年最令人印象深刻的演示是实时语音和摄像头功能。
我最喜欢的是 OpenAI 的 “Be My Eyes” 演示,展示了一个盲人用户使用他们的手机摄像头扫描房间,同时与 GPT-4V 进行对话,后者可以实时描述它看到的内容。
这些功能现在已经在多个应用程序中提供。我最喜欢的是 Claude 的网络界面,它可以让你与模型进行语音对话,同时显示一个实时的文字记录。
提示词驱动的应用生成已成为一种商品
去年,我写道”提示词工程”作为一项技能正在消失,因为模型变得更好了。
这个趋势在 2024 年加速了。现在有数十个工具可以从自然语言描述中生成完整的应用程序,包括:
- 用于构建网站的 v0.dev
- Microsoft Copilot 的 “创建应用程序” 功能
- Claude 的 “项目” 功能,可以生成完整的 Python 应用程序
这些工具的输出质量令人印象深刻。它们生成的代码通常可以直接运行,包括所有必要的依赖项。
更重要的是,这些工具现在足够好,可以用于生产用途。我已经开始在我的个人项目中使用它们了。
我最喜欢的例子是 django-http-debug,这是一个我在 8 月份发布的 Django 调试工具。它的大部分代码都是由 Claude 生成的,我只需要做一些小的修改就可以了。
这种能力的普及化意味着,对于许多项目来说,最大的挑战不再是编写代码,而是准确地描述你想要构建什么。
最佳模型的普遍访问仅持续了短短几个月
2024 年初,任何人都可以访问最好的模型。GPT-4 是通过 ChatGPT Plus 提供的,Claude 2.1 是免费的,Gemini Pro 也是免费的。
到年底,情况发生了变化。最好的模型现在都隐藏在企业付费墙后面,或者完全不对外提供。
这是一个令人失望的发展。我理解商业现实,但我仍然希望能有一种方式让研究人员和业余爱好者能够访问最先进的模型。
“智能体”仍然没有真正实现
2024 年是”智能体”年 - 每个人都在谈论它们,但没有人真正知道它们是什么。
我认为最好的定义是”一个可以采取行动的大语言模型”。但即使有了这个定义,我们仍然没有看到任何真正令人印象深刻的智能体出现。
最接近的可能是 Claude 的”计算机使用”功能,它可以让模型在沙盒环境中运行代码。但这更像是一个增强的 REPL 而不是一个真正的智能体。
我认为问题在于,我们仍然不知道如何让大语言模型可靠地完成多步骤任务。它们在单次交互中表现出色,但一旦你要求它们执行一系列操作,它们就开始出错。
评估变得非常重要
随着越来越多的模型达到 GPT-4 级别的性能,评估变得越来越重要。
最有影响力的评估是 Chatbot Arena,它使用人类反馈来对模型进行排名。但我们也看到了更多自动化评估的出现:
- Anthropic 的 Constitutional AI 评估
- Google 的 PaLM 2 评估套件
- OpenAI 的 GPT-4 评估
- Meta 的 Llama 2 评估
这些评估帮助我们理解模型的能力和局限性。但它们也有局限性:它们往往专注于容易量化的事物,而忽视了更难衡量的品质。
Apple Intelligence 表现不佳,但 Apple 的 MLX 库非常出色
Apple 在 2024 年的 AI 战略令人困惑。
一方面,他们推出了 MLX - 一个出色的机器学习框架,专门为 Apple Silicon 优化。这个框架使得在 Mac 上运行大语言模型变得更容易。
另一方面,他们的 Apple Intelligence 产品(包括 Siri 和其他 AI 功能)仍然远远落后于竞争对手。
这种矛盾让人困惑。Apple 显然有能力构建出色的 AI 工具,但他们似乎不愿意在消费产品中使用它们。
推理扩展模型的崛起
2024 年最有趣的技术发展之一是”推理扩展”模型的出现。
这些模型专门设计用于处理长文本和复杂推理任务。它们不是通过增加参数数量来实现这一点,而是通过改变模型的架构。
最著名的例子是:
- Anthropic 的 Claude 3 系列
- Google 的 Gemini 系列
- Meta 的 Llama 3 系列
这些模型能够处理比传统 Transformer 架构更长的序列,并且在需要多步推理的任务中表现更好。
目前最好的大语言模型是在中国以不到 600 万美元的成本训练的吗?
2024 年最令人惊讶的发展之一是中国模型的崛起。
特别是 01.AI 的 Yi-34B 模型引起了广泛关注。这个模型:
- 在多个基准测试中击败了 GPT-4
- 只用了 600 万美元就完成了训练
- 完全开源
这引发了一个有趣的问题:为什么其他组织花费如此多的资金来训练他们的模型?
可能的解释包括:
- 中国的计算成本更低
- 01.AI 发现了一些新的训练技巧
- 基准测试可能不能完全反映模型的真实能力
无论如何,这都是一个重要的发展,表明大语言模型的训练成本可能比我们想象的要低得多。
环境影响变好了
好消息是,大语言模型的环境影响在某些方面有所改善:
- 训练效率提高了
- 推理效率提高了
- 更多的模型可以在本地设备上运行
- 可再生能源的使用增加了
环境影响变得更糟了
坏消息是,整体的环境影响可能变得更糟了:
- 模型数量激增
- 使用量大幅增加
- 更大的模型需要更多的计算资源
- 数据中心的扩张
这是一个复杂的问题,没有简单的解决方案。我们需要继续提高效率,同时也要考虑是否每个用例都真的需要大语言模型。
垃圾内容之年
2024 年见证了 AI 生成内容的爆炸式增长。这导致了大量的”垃圾”内容:
- AI 生成的博客文章
- 自动生成的视频
- 合成的社交媒体帖子
- 虚假的产品评论
- 垃圾电子邮件
这个问题变得如此严重,以至于”垃圾”成为了描述这种内容的标准术语。
搜索引擎和平台正在努力应对这个问题,但目前还没有完美的解决方案。
合成训练数据效果很好
2024 年最有趣的发现之一是合成训练数据的有效性。
多个研究团队发现,使用大语言模型生成的训练数据可以产生与使用人类生成的数据相当的结果。
这有几个重要的含义:
- 训练数据的获取成本可能会大幅降低
- 我们可以生成更多样化的训练数据
- 数据隐私问题可能会减少
但这也引发了一些担忧:
- 模型可能会继承生成数据的偏见
- 我们可能会创建越来越多的”回声室”
- 合成数据可能缺乏真实世界的细微差别
大语言模型的使用变得更加困难
随着模型变得更加强大,它们也变得更难使用。
这听起来可能有点矛盾,但考虑以下几点:
- 更多的功能意味着更多的选项
- 更长的上下文长度需要更好的提示工程
- 新功能(如代码执行)带来了新的安全考虑
- 不同模型之间的差异越来越大
这导致了一个有趣的现象:尽管模型变得更强大,但充分利用它们的能力变得更具挑战性。
知识分布极不均衡
大语言模型领域的知识分布仍然非常不均衡。
一些组织和个人似乎掌握了”秘密知识”,而这些知识并没有得到广泛传播。这包括:
- 训练技巧
- 提示工程技术
- 评估方法
- 部署最佳实践
这种不均衡部分是由于:
- 商业秘密
- 快速的技术发展
- 文档的缺乏
- 知识传播的障碍
大语言模型需要更好的批评
最后,我认为我们需要更好的方式来批评和讨论大语言模型。
目前的讨论往往陷入两个极端:
- 过度乐观:认为大语言模型将解决所有问题
- 过度悲观:认为它们完全没用或者极其危险
我们需要更细致的讨论,承认:
- 这些工具确实有价值
- 它们也有严重的局限性
- 使用它们需要深思熟虑
- 我们需要认真对待潜在的负面影响
只有通过更好的批评和讨论,我们才能确保这项技术的发展方向是积极的。
本文翻译自 Simon Willison 的博客文章 Things we learned about LLMs in 2024。